Jump to:
Languages:
C/C++,
Java,
Perl,
Python,
Ruby,
Octave,
Scheme,
Bash
Misc:
Other Sources of Entropy,
Implementation Notes,
Sample Code
C/C++
In C/C++, pseudo-random integers distributed uniformly (/semi-uniformly) along the range 0 to some value, RAND_MAX, can be generated by calling the rand() function. While on some platforms there are functions that return better sequences of pseudo-random values, one advantage of rand() is that it's specified in the ANSI/ISO C standard. Thus, code that uses it will be more portable than code that uses alternatives such as random() or members of the rand48 family such as lrand48() or drand48().
Even though ANSI C requires the existence of a function rand() that generates sequences of pseudo-random integers, it leaves the particular algorithm to be used unspecified. However, it does give the following portable sample implementation using a linear congruential generator:
static unsigned long int next = 1;
int rand(void) // RAND_MAX assumed to be 32767
{
next = next * 1103515245 + 12345;
return (unsigned int)(next/65536) % 32768;
}
Note that the above code sample conforms to the requirement that RAND_MAX is at least 32767, and that the default random seed is 1.
GNU C LibraryIn the GNU C Library, both rand() and random() share the same underlying implementation. This can be seen on line 28 in glibc-2.3.6/stdlib/rand.c (or, alternatively "man 3 rand" on a Linux box should work, too). By default, the implementation uses a linear feedback shift register with 128 bytes of state information to generate random integers ranging from 0 to a RAND_MAX of 231-1. The amount of state information used can be modified by calling initstate(), and is allowed to range from 8 to 256 bytes. However, if fewer than 32 bytes are used, the code back-offs to using a linear congruential generator.
The generator operates by having two integer pointers into an array of state information. Each time a random number is requested, the corresponding values in the state array are summed. The result of the summation is then stored in the state array, replacing the value pointed to by one of the pointers. This new value is also subsequently used as the random value generated by the algorithm. However, since the new value is a 32-bit integer and only 31-bits are needed in order to get a random number in the desired range, the least significant bit is dropped in order to get the final random value returned by the routine. After generating and storing the new random value, both of the state pointers are incremented so that they point to subsequent locations in the state array. If either pointer reaches the end of the array, it is reset to point to the beginning of it.
Below is the snippet of the code that gets executed to generate the successive random values:
val = *fptr += *rptr;
/* Chucking least random bit. */
*result = (val >> 1) & 0x7fffffff;
++fptr;
if (fptr >= end_ptr)
{
fptr = state;
++rptr;
}
else
{
++rptr;
if (rptr >= end_ptr)
rptr = state;
}
Above, fptr and rptr are pointers to 32-bit integers inside the state array. The pointer result is used to store the random value that will be returned by function. The initial state array is populated with values generated using a linear congruential random number generator. The pointer rptr is initialized to point to the beginning of the state array, while the initial location pointed to by fptr varies according to the size of the state array (for the default state array size of 128 bytes, &state[3] is used).
Recall that the period of a random number generator is the number of random values that it generates before the sequence repeats itself1. For this generator, the size of the period will depend on the amount of state information used. According to the Linux man page for random(), when using the default of 128 bytes of state information, the period is approximately 16*(231-1).
Java
In Java, the class Random from the package java.util can be used to generated pseudo-random values for a variety of data types, specifically, boolean, byte, int, long, float, and double. For doubles, random values can be generated along both a uniform distribution in the range [0,1)2, and a Gaussian distribution with mean 0.0 and standard deviation 1.0. For integers, random values are uniformly distributed across all the values that can be represented using a 32-bit signed integer, [-231,231-1].
Internally, all random values generated by objects of this class are produced by calling the method next(int bits) that returns an integer with the requested number of random bits. This value is then used to generate the various type specific random values. The implementation is convenient as it allows subclasses of Random to simply replace this method with one that implements an alternative pseudo-random number generator and then all of the other type specific methods will generated random values using the new algorithm.
To generate random values, next() uses the following linear congruential pseudo-random number generator.
synchronized protected int next(int bits) {
seed = (seed * 0x5DEECE66DL + 0xBL) & ((1L << 48) - 1);
return (int)(seed >>> (48 - bits));
}
Java 5, J2SE API documentation - Random.next()
In an alternate notion, the recurrence for this generator is then:
Note that, even though seed is stored as a long, Java's signed 64-bit integer type, only 48 bits of state information are stored in it. Further, the constant multiplier, 0x5DEECE66D, and increment, 0xB, are identical to those used for the popular rand48 family of linear congruential random number generators found on many Unix/Unix-like systems. Additionally, a library routine from this family of generators, drand48(), is also Perl's preferred generator on platforms that support it.
The given recurrence has a period length of 248 (this is order 1014). As such, since the modulus is also 248, the underlying generator can be said to have a full period.
Perl
In Perl, real valued uniformly distributed pseudo-random numbers can be obtained by calling the function rand(). This function takes one argument that specifies the upper limit on the range of random values. That is, rand(n) will return a real valued random number in the range [0,n). This value can then be passed to int() if random integer values are desired. Rather than rounding to the nearest integer, int() just removes the decimal portion of it's argument. This truncation is actually desirable in this case, since it results in random integer values that are still uniformly distributed in the range [0,n). If rounding was performed, '0' would be less probably than all of the other integers in the original range, and the range would change to [0,n] (i.e. the ranges now includes the end point n).
Perl generates random numbers using the library routines provided by the platform it has been complied for. Specifically, Perl's first choice is to use drand48(). However, if it is not available, it will try to use random(). If both of these are unavailable, it will settle for rand(). Perl's configuration script has somewhat amusing commentary on its preferences regarding the three routines:
if set drand48 val -f; eval $csym; $val; then
dflt="drand48"
echo "Good, found drand48()." >&4
elif set random val -f; eval $csym; $val; then
dflt="random"
echo "OK, found random()." >&4
else
dflt="rand"
echo "Yick, looks like I have to use rand()." >&4
fi
Python
In python, random numbers can be generated using the module random. This module not only provides routines for generating uniformly distributed integer and real valued pseudo-random numbers, but also provides routines for real valued numbers distributed along a sizable number of different distributions (e.g. beta, exponential, gamma, Gaussian, Pareto, and Weibull distributions). Additionally, there are routines for shuffling sequences and sampling from a collection.
The module is implemented using a hidden object instantiated from the class random.Random. The functions in the module simply invoke the corresponding methods in this object. The Random class itself is organization in a manner similar to Java's Random class where by, if you recall, all the methods for generating random values depend on the method next(). In Python's case the core method's name is random(), and it generates real valued numbers in the range [0,1). As with Java, to replace the pseudo-random number generator used by all the methods in the class, one can simply subclass Random and supply a new implementation of the core generator, random().
Starting with CPython 2.3, the method random() uses a Mersenne Twister pseudo-random number generator. This is a fairly new technique that has been shown to result in generators with impressive periods and otherwise good sequences of pseudo-random numbers. More concretely, for the set of parameters used in the variant/implementation known as MT199937, the generator has an enormous period of 219937-1 (this is on the order of 106001). The approach and the MT19937 variant were introduced in the following paper by Makoko Matsumoto and Takuji Nishimura.
Matsumoto and Nishimura also made a C-code implementation of MT19937 available under a fairly liberal open source license. With a few mirror changes in order to integrate the code into CPython, it is the 2002/1/26 release of this MT19937 implementation that acts as the underlying generator for the random() method (see Python-2.4.2/Modules/_randommodule.c). The original unmodified code is available for download from the official Mersenne Twister Home Page
Ruby
Pseudo-random numbers can be generated in Ruby by the Kernel method rand(). This routine takes one argument dubbed max. If the magnitude of max is greater than or equal to 1.0, then rand() returns an integer uniformly distributed in the range [0,max.to_i.abs]. In this context, like Perl's int() routine, the method to_i() returns just the integer portion of a real valued number without any rounding and the method abs() simply takes the absolute value of the resulting integer. However, if the magnitude of max is less than 1.0 but not 0.0, rand() returns a real valued number uniformly distributed in the range [0,max.abs). If max is zero, the default value if no parameter is explicitly supplied, rand() returns a real valued number in the range [0,1).
Like python, Ruby uses a Mersenne Twister pseudo-random number generator. In fact, it also uses the MT19937 C-code released by Matsumoto and Nishimura (see ruby-1.8.3/random.c). However, Ruby uses a variant released on 2002/2/10 that is potentially faster on some platforms, but it has been reported to be slower on Pentium 4 systems. On the Mersenne Twister homepage this release is listed as a "version considering Shawn Cokus's code", and dated 2002/2/11.
Octave
Pseudo-random real valued numbers can generated in Octave using the functions rand() and randn(). Additionally, a row vector with a random permutation of integers can be generated using randperm(). If the routines rand() and randn() are called without any arguments, they both produce a single random value. However, if they are called with a single numeric argument, n, they will generate a square n-by-n matrix of random values. If they are called with two arguments, say n and m, they will generate a n-by-m matrix of random values. The two routines differ in that randn() generates values that have a Gaussian distributed with mean 0 & standard deviation 1, while rand() generates values uniformly distributed in the range (0,1) (see: octave-2.1.72/libcruft/ranlib/genunf.f). Note that the latter differs from the other similar routines previously presented that generate values in the range [0,1)2.
The values returned by rand() and randn() are generated using routines from Ranlib, a library of C and Fortran routines for generating pseudo-random numbers. The package is maintained by Barry Brown of the Department of Biostatistics & Applied Mathematics at the University of Texas, MD Anderson Cancer Center, and can be downloaded from the department's software repository.
The package generates random numbers by combining the output of two multiplicative linear congruential generators. Doing so results in an aggregate generator that has a period of 2.3 x 10 18. The implementation of this generator is based on a Fortran 77 port of the Pascal source code that appears in the appendix of the following paper:
Note that, this paper focuses on providing simultaneous access to multiple generators each of which that has its output organized into a series of substreams/blocks. Generators can be maneuvered among and within the blocks through instructions to transition to the next block, restarted within the current block, and restart at it's first block. While this functionality is provided by Ranlib, it does not appear to be used by Octave.
Scheme
Pseudo-random numbers can be generated in Scheme using the procedure random. This procedure takes one argument, named modulus, and returns values uniformly distributed in the range [0,modulus). If the specified modulus is of type integer, the routine will return integer random values. Similarly, if a real valued modulus is used, the routine will return a real valued random number.
Implementation in GuileIn Guile, an implementation of Scheme targeted as being an "extension language" (/embedded scripting language) for other applications, random numbers are generated using a Multiply with Carry generator. This class of generators was first proposed in a Usenet post by George Marsaglia in sci.stat.math titled "Yet another RNG" on August 1, 1994. At the time, Marsaglia was so excited about this class of generators that he informally dubbed them "The Mother of All Random Number Generators" due to the long periods that could be generated using a relatively simple and efficient algorithm.
Multiple-with-Carry (MWC) generators produce values using the following recurrence:
Here carry can be defined as:
However, since MWC generators use a modulus, M, that is a power of two, r and carry are really just the low and high order bits, respectively, of the same underlying recurrence.
Within Guile, it's MWC generator is implemented by the following code snippet. A variant of this generator is also provided for systems that don't support 64-bit integer types. While slightly more complex, the alternate generator still implements the same underlying computation.
unsigned long
scm_i_uniform32 (scm_t_i_rstate *state)
{
LONG64 x = (LONG64) A * state->w + state->c;
LONG32 w = x & 0xffffffffUL;
state->w = w;
state->c = x >> 32L;
return w;
}
In the code above, the basic recurrence is computed and then stored in a 64-bit temporary variable x. The high order bits are then stored in the carry, state->c, and the low order bits are stored in state->w and then returned as the random value produced by the generator.
The generator has a period of approximately 4.6 x 1018, or alternatively about 262;
Bash Shell Script
Pseudo-random integer values can be obtained in Bash by retrieving values from the special shell variable RANDOM. Each time a value is read from this variable, Bash generates a random integer (semi-)uniformly distributed in the range [0,32767]. If a value is assigned to RANDOM, the value is used as a new random seed for the generator. The variable RANDOM can also be used to generate integer values in Z shell (zsh) and Korn Shell (ksh). However, it isn't support by the original Bourne shell (sh).
Retrieving values from RANDOM in bash invokes the following linear congruential pseudo-random number generator. Here, rseed is an unsigned long that is initialized to 1, but then later set to the sum of the current process id and the shell start time.
/* Returns a pseudo-random number between 0 and 32767. */
static int
brand ()
{
rseed = rseed * 1103515245 + 12345;
return ((unsigned int)((rseed >> 16) & 32767)); /* was % 32768 */
}
From bash-3.1/variables.c lines 1146-1152
If you recall, this is the exact same generator given in the ANSI/ISO C Standard as the example implementation of the rand() function. The code snippets only differ in the manner that they remove the 16 low order bits from the state variable (rseed/next) and then ensure that the resulting integer is in the range [0,32767] across all platforms. Specifically, in Bash, this is done using universally fast bit manipulation operators, while, in the Standard C example code, this is done using division and modulus operations; i.e. ((rseed >> 16) & 32767) vs. ((next/65536) % 32768). However, it is interesting to note that the GNU C compiler and presumably other modern C compilers actually compile both variants of these two operations to the same pair of processor instructions:
sar eax, 16 ; shift-16/divide-65536 operation
and eax, 32767 ; and-32767/modulus-32768
Other Sources of Entropy
In some domains, such as cryptography, the pseudo-random number generators discussed above may not be entirely appropriate due to their deterministic nature. That is, given a known initial state, such generators will always produce the exact same sequence of random values. On Unix, Linux and other Unix-like platforms an alternative source of entropy is the special file /dev/random. Values read from this file represent random numbers generated by the operating system using various system events to create a pool of entropy. Since such systems events can be based on random events in the external environment, the generated values are much more like true random numbers. Additionally, on Microsoft Windows the routine CryptGenRandom can be used for generating random values targeted for use in cryptography. In contrast to /dev/random, this routine doesn't appear to automatically use random system events to generate random values. However, it does allow the calling routine to supply a buffer containing an "auxiliary random seed" that can be filled with random environmental noise that has been collected by the calling application.
Implementation Notes
The sample code given below for generating random numbers takes two parameters, one specifying the type of random value to be generated ("int" or "real") and the other indicating how many random values should be produced. The random seed is left to whatever the default is for the routines used in the respective languages. This means that for the C, C++, and (Guile interpreted) Scheme implementations the sequence of random values will be identical across separate invocations, while for the other implementations the sequence will differ.
Footnotes:
- see the description of period included with the Randu post from last week.
- [0,1) Indicates that the range is includes '0' but excludes '1'. In contrast, (0,1) indicates that the range excludes both '0' and '1'
Source files:
LibraryRandomNumber.c [raw code], LibraryRandomNumber.cc [raw code], LibraryRandomNumber.java [raw code], LibraryRandomNumber.pl [raw code], LibraryRandomNumber.py [raw code], LibraryRandomNumber.rb [raw code], LibraryRandomNumber.m [raw code], LibraryRandomNumber.scm [raw code], LibraryRandomNumber.sh [raw code],
Randu is a pseudo-random number generator dating back to the 1960s that was included in IBM's scientific subroutine package for System/360 mainframe computer systems. It generates successive random numbers by using the following recurrence:
ri+1=65539 * ri modulo 231Here, the initial value, r0, is known as the random seed.
Note that, due to the choice of the multiplier and modulus, this algorithm can be implemented using just a handful of add and bit manipulation operations (see the C, C++, or Java implementations below). This was intentional as it allowed for a particularly efficient implementation on early computer systems. However, it later fell out of favor due to a number of undesirable properties in the sequence of values it generated that can be attributed to its given multiplier and modulus. For instance, if the coordinates for a large number of 3-dimensional points are generated using Randu, all of the points will be found to lie along 15 planes. This phenomena is shown below in a scatter plot of 10,000 Randu generated points. Ideally, such pseudo-randomly generated points should fairly uniformly fill the cube, as would happen if a set of truly random points were used.
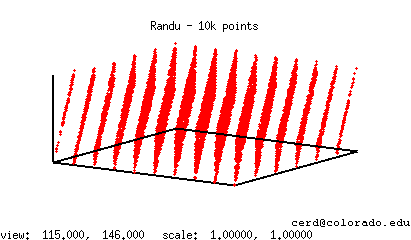
Additionally, this generator lacks a full period. That is, random number generators defined by a recurrence like the one above will eventually produce a value that was previously seen earlier on in the sequence. When this happens, the subsequent sequence of values generated will be identical to the sequence previously generated after the repeated value. For example, if Randu is started with a random seed of 1 and is allowed to run indefinitely, then it will generate a sequence like the following:
65539, 393225, 1769499, 7077969, 26542323.....1, 65539, 393225, 1769499, 7077969, 26542323..... 1, 65539, 393225, 1769499, 7077969, 26542323.....
The period of a random number generator is the number of values it outputs prior to repeating itself. A generator that produces values modulo some value m, is seen to have a full period if the period length is equal to m. Put another way, a generator has a full period if it produces all integer values in the range [0,m). Randu's maxium period length is only 229, which is observed whenever Randu is started with an odd random seed. Thus, it can only generate a forth of the values in the range [0,231).
Finally, in many of the code samples below, the state of the generator is stored as a global variable. While the use of global variables is generally undesirable, this matches the implementation of random number generators in many older standard libraries.
Source files:
Randu.c [raw code], Randu.cc [raw code], Randu.java [raw code], Randu.pl [raw code], Randu.py [raw code], Randu.rb [raw code], Randu.m [raw code], Randu.scm [raw code], Randu.sh [raw code],
In order to make things a bit more interesting, the code actually finds all instances of a search term in a given list. For this slightly extended task, most of the code samples are pretty efficient as they effectively just walk through the list and note all of the occurrences of the search term. That is, for a list of n-items, such code has a time complexity of O(n). However, this is not true for all of the code samples. For instance, the Java code given here is fairy inefficient, as it repeatedly: (a) performs a linear search starting at the beginning of the list; (b) if it finds a match, the entry is removed from the list before performing step (a) again in order to search for additional matches. While always starting the search from the beginning of the list in step (a) is clearly wasteful, step (b) is also fairly costly. This is due to the list being stored as an ArrayList, and thus every time an item is removed, the remaining items that followed the deleted one in the list must each be shifted over 1 position in order to fill the newly created gap. Moreover, both step (a), with its restarting of the search at the beginning of the list, and step (b), with its shifting of the contents of the array, are sufficient, even in isolation, to increase the time complexity required to find m matching terms in a list of n-item to O(n*m). Since m could, in principle, equal the length of the list, that is every entry in the list could be the search term that we're looking for, the time complexity can be given as O(n2).
Miscellaneous notes: Most of the code supports searching through lists of arbitrary strings. However, the Octave code only allows for lists of floating point numbers. Also, the C implementation is limited to lists containing strings no longer than 1024 characters.
Source files:
LinearSearch.c [raw code], LinearSearch.cc [raw code], LinearSearch.java [raw code], LinearSearch.pl [raw code], LinearSearch.py [raw code], LinearSearch.rb [raw code], LinearSearch.m [raw code], LinearSearch.scm [raw code], LinearSearch.sh [raw code],
Conceptually, this algorithm operates by maintaining two lists; one that is sorted and another unsorted one that contains items not yet examined by the algorithm. Initially, the sorted list is empty, and the unsorted list contains the original list passed as input to the algorithm. During each iteration, the algorithm removes one item from the unsorted list and inserts it into the appropriate location in the sorted list. It then terminates when there are no more items left in the unsorted list.
If the lists are stored as arrays, inserting an item into the sorted list involves both locating the appropriate insertion point and then shifting over existing values in order to make room for the new one. A typical implementation, illustrated in the code below, involves using a single array for both the sorted list and the unsorted list. Specifically, the first half of the array, represents the sorted list, while the later half of the array represents the unsorted list. The next item selected for insertion into the sorted list is then always the item in the unsorted list that lies directly on the boundary of the two.
The code uses a linear search, starting at the end of the sorted list, in order to find the appropriate insertion point. It combines this linear search with the shifting of the contents of sorted list. For the i-th item being inserted into the sorted list, this linear search/shift step involves, in the worst case, (i-1) comparisons/shifts. Thus, for a list of N items, if we experience the worst case for each of the inserted items, N(N-1)/2 comparisons/shifts are required. This gives the algorithm a time complexity of O(n2), like that of both Bubble sort and Selection sort. However, insertion sort tends to be greatly more efficient than both of these.
Source files:
InsertionSort.c [raw code], InsertionSort.cc [raw code], InsertionSort.java [raw code], InsertionSort.pl [raw code], InsertionSort.py [raw code], InsertionSort.rb [raw code], InsertionSort.m [raw code], InsertionSort.scm [raw code], InsertionSort.sh [raw code],
The algorithm operates by iterating over a list and swapping, in place, every pair of adjacent items that are not in the correct order. After iterating through the list once, the list's values will not necessarily be in the correct sort order. Rather, for a list of N items, N passes over the list maybe necessary to ensure that all of the values are property sorted. However, after the i-th pass through the list, the last i values in it will be in their correct and final locations. As such, each pass only really needs to operate over N-i items. Additionally, if during any pass, no swaps are necessary, then the list is already sorted and the algorithm can terminate early.
If implemented with such early stopping, as seen in the code samples below, and if bubble sort is given an already sorted listed, then only one pass through the list, consisting of N-1 iterations, will be required [Note: each pass through the list that operates over n items, will only require n-1 iterations since there are only n-1 adjacent locations in a sequence of n items]. This being the best case for the algorithm. However, if the algorithm must make all N passes through the list, ((N-1)N)/2 iterations will be needed. As such, the algorithm has a time complexicty of O(n2).
Source files:
BubbleSort.c [raw code], BubbleSort.cc [raw code], BubbleSort.java [raw code], BubbleSort.pl [raw code], BubbleSort.py [raw code], BubbleSort.rb [raw code], BubbleSort.m [raw code], BubbleSort.scm [raw code], BubbleSort.sh [raw code],
A selection sort is probably one of the most intuitive & easy to understand sorting algorithms. The algorithm operates by iterating over a list and finding during the i-th iteration the smallest value in the list that has an index (think position in the list) greater than or equal to i. The value that is found is swapped with the value in the i-th position in the list. Accordingly, after the 1st iteration, the smallest value in the list will be in the first position in the list. And, after the second, the second smallest value in list will be in the second position. This continues until the list is completely sorted.
During each iteration, the i-th smallest value is found by iterating over all of the currently unsorted values and finding the minimum value. As such, the algorithm effectively has both an inner and and outer loop. The outer loop is executed N times, where N is the number of items in the list. For each iteration of the outer loop, the inner loop executes N-i times. Thus, for a list of n items, the total number of iterations preformed by the algorithm will ben(n+1)/2, or rather of order n2. This means that, in big-O notation, the algorithm has a time complexity of O(n2).
Source files:
SelectionSort.c [raw code], SelectionSort.cc [raw code], SelectionSort.java [raw code], SelectionSort.pl [raw code], SelectionSort.py [raw code], SelectionSort.rb [raw code], SelectionSort.m [raw code], SelectionSort.scm [raw code], SelectionSort.sh [raw code],
Description: Code that sorts a list of floating point numbers using each language's built-in/standard-library support for sorting. For the case of the Bourne shell script, the notion of build-in support is extended to include utilities commonly installed on Unix/Unix-like environments (e.g. this includes Linux, Mac OS X, & Cygwin).
Source files:
LibrarySort.c [raw code], LibrarySort.cc [raw code], LibrarySort.java [raw code], LibrarySort.pl [raw code], LibrarySort.py [raw code], LibrarySort.rb [raw code], LibrarySort.m [raw code], LibrarySort.scm [raw code], LibrarySort.sh [raw code],
Description: Code to list the files & sub-directories contained within a user specified directory. For both Perl & Python, two scripts are given. One that uses each language's respective 'glob' support for listing files & directories that match a particular pattern, and one that uses simpler (/conceptually more-direct) routines provided by the two languages. Also, the Bourne shell code contains a 'for' loop even though technically this isn't necessary, but rather is just there to make the code modestly more interesting.
Source files:
ListFiles.c [raw code], ListFiles.cc [raw code], ListFiles.java [raw code], ListFiles.pl [raw code], ListFiles_glob.pl [raw code], ListFiles.py [raw code], ListFiles_glob.py [raw code], ListFiles.rb [raw code], ListFiles.m [raw code], ListFiles.scm [raw code], ListFiles.sh [raw code],
Description: Code that uses an iterative algorithm to calculated the n-th fibonacci number, where by 'n' is specified by the user on the command line. This is a much more efficient way to calculate Fibonacci numbers than the previously posted 'Recursive Fibonacci'.
Source files:
FibonacciIter.c [raw code], FibonacciIter.cc [raw code], FibonacciIter.java [raw code], FibonacciIter.pl [raw code], FibonacciIter.py [raw code], FibonacciIter.rb [raw code], FibonacciIter.m [raw code], FibonacciIter.scm [raw code], FibonacciIter.sh [raw code],
Description: Code that recursively calculates the n-th fibonacci number, where by 'n' is specified by the user on the command line. Note that is a terribly inefficient way to calculate Fibonacci numbers.
Source files:
FibonacciRecur.c [raw code], FibonacciRecur.cc [raw code], FibonacciRecur.java [raw code], FibonacciRecur.pl [raw code], FibonacciRecur.py [raw code], FibonacciRecur.rb [raw code], FibonacciRecur.m [raw code], FibonacciRecur.scm [raw code], FibonacciRecur.sh [raw code],
Description: Code to display the contents of one or more files specified on the command line.
Source files:
DisplayFiles.c [raw code], DisplayFiles.cc [raw code], DisplayFiles.java [raw code], DisplayFiles.pl [raw code], DisplayFiles.py [raw code], DisplayFiles.rb [raw code], DisplayFiles.m [raw code], DisplayFiles.scm [raw code], DisplayFiles.sh [raw code],
Description: Code to print command line arguments to the console.
Source files:
PrintCommandArgs.c [raw code], PrintCommandArgs.cc [raw code], PrintCommandArgs.java [raw code], PrintCommandArgs.pl [raw code], PrintCommandArgs.py [raw code], PrintCommandArgs.rb [raw code], PrintCommandArgs.m [raw code], PrintCommandArgs.scm [raw code], PrintCommandArgs.sh [raw code],
Description: Code that prints "Hello world" to the console.
Source files:
HelloWorld.c [raw code], HelloWorld.cc [raw code], HelloWorld.java [raw code], HelloWorld.pl [raw code], HelloWorld.py [raw code], HelloWorld.rb [raw code], HelloWorld.m [raw code], HelloWorld.scm [raw code], HelloWorld.sh [raw code],



![[Valid RSS]](/renma/images/valid-rss.png "Validate my RSS feed")
